
目录
一、机器决策导入库以及相关的学习幸存数据
1.导入所需要的库
2.导入指定的数据集
3.查看数据的相关信息
1.data.info()
2.data.head()
二、数据的笔记预处理
1.处理数据中的空缺值
2.将非数字的特征转换成数字
警告提示的解释
3.将特征和标签分开提取
1.提取特征
2.提取标签
三、将数据导入模型进行训练
1.划分测试集和训练集
2.将测试集和训练集中被打乱的树泰索引排序
3.带入模型
四、优化模型
1.使用交叉验证
2.测试不同的坦尼树深度对于分数的影响
1.循环测试,存储每一次的克号结果
2.画图分析
3.测试看看别的不纯度的指标对模型打分的影响
1.循环测试,存储每一次的预测结果
2.画图分析
4.使用网格搜索
*的自动拆包作用
linspace和arange的区别
网格搜索的两个重要接口 GS.best_params_和GS.best_score
带入验证
一、导入库以及相关的机器决策数据
1.导入所需要的库
#1.导入所需要的库import pandas as pdfrom sklearn.tree import DecisionTreeClassifierimport matplotlib.pyplot as pltfrom sklearn.model_selection import GridSearchCV2.导入指定的数据集
#2.导入数据集,探索数据#加上r 就是学习幸存保持字符串原始值的含义,即不对其中的符号进行转义#在windows的环境下的话路径的分隔符"\",所以会发生转译#但是笔记在macOS或者Linux下不加r也是可以正常读取到数据的#当前我用的是macOS,但是树泰为了记录这一点,还是坦尼写一个r并在此说明一下data=pd.read_csv(r"/Users/Documents/data.csv")数据集可以从下面的网盘中提取
链接: https://pan.baidu.com/s/1mb1pVmNdcWLqh3Cd0Rg1tA?pwd=20np 提取码: 20np
3.查看数据的相关信息
1.data.info()
#查看数据集的相关信息#一般就是使用下面的这两个方法data.info()#Column对应的是特征的名字#Non-Null Count是非空元素的个数统计#Dtype是具体的元素类型#我们的决策树的分类器只能处理数字,所以我们的克号标签的类型必须是数字#二分类的话就是0、1,预测三分类的机器决策话就是1、2、3,不能是文字#所以如果下面的特征是object的类型的话,都需要转换成数字才能够使用#并且想Cabin的数据存在大量的缺失值,这些我们都是需要处理的
2.data.head()
#查看这张表的前n行数据data.head(n),n不写默认是5data.head()
二、数据的预处理
1.处理数据中的空缺值
#3.数据的预处理#筛选特征#像name和ticket等不太容易转化为数字特征值的数据,并且和存活率也没有太大的关系的可以忽略这个特征#像Cabin特征,我们之前看到它缺失了大概70%左右的数据,咱们也可以忽略#data.drop可以删除指定的数据,后面传入的是索引#inplace=True,就是用删除完毕的表去覆盖原表,默认的是FALSE,也就是返回一张新的表,但不会修改原来的表#axis=1对列进行操作,也就是删除列data.drop(["Cabin","Name","Ticket"],inplace=True,axis=1)data
#处理缺失值#对于age数据大概缺失了200个左右的数据,并且age对于我们的结果可能是会有影响的,#所以我们在这里填补我们的age数据#fillna,填补缺失值,并且用年龄这一列的平均值去填补#为什么年龄可以用平均值去填补?#因为我们可以假设这些缺失数据的人的年龄就是这个平均水平,不管老少,都是这个水平#虽然给模型添加了一些噪声,但是量不大data['Age']=data["Age"].fillna(data['Age'].mean())data.info()
#我们观察到embarked的数据缺失了两个#这种情况下我们最好的处理方式是将这两个数据所在的整行删掉,因为这个数据量太少了,不会影响整体的结果#将含有缺失值的行删掉,默认axis=0可以不用写data=data.dropna(axis=0)data.info()
data.head()
2.将非数字的特征转换成数字
#我们之前说过决策树是没办法处理非数字的标签的#所以我们需要将性别和Embarked转换为具体的数字#首先查看embarked中到底有多少类,也就是将重复值全部都去除掉,看看一共有多少个值#我们不需要数组,我们需要使用tolist将其转换成一个列表labels=data["Embarked"].unique().tolist()labels![]()
#将我们的Embarked这一列替换成数字#apply就是在指定的列上执行apply中的操作#下面的代码就是对data的Embarked列执行将其中的所有列表项都按照labels转换为对应的索引#也就是将S转换为0,C转换为1,Q转换为是2data["Embarked"]=data["Embarked"].apply(lambda x:labels.index(x))
解释上面代码中的labels.index(x)
#index中传入具体的值,它会返回其对应的位置,也就是说我们的S在的0号位置labels.index("S")![]()
data
#将性别也转换成二分类#会返回一系列的布尔值,TRUE代表是男的,FALSE代表是女的data["Sex"]=="male"
#将布尔值转换为整数,TRUE是1,FALSE是0(data["Sex"]=="male").astype("int")
data["Sex"]=(data["Sex"]=="male").astype("int")
这时我们Sex列的数据就全部被转换成了0,1,男的是1,女的是0
data
警告提示的解释
#上面的出现的大段提示是# A value is trying to be set on a copy of a slice from a DataFrame.#Try using .loc[row_indexer,col_indexer] = value instead#也就是说上面我们这种写法马上就要被删掉了,最好使用loc索引的形式,也就是我们下面的写法#下面的loc就是将所有的行和Sex这一列相交的位置的元素取出来,也就是我们的Sex这一列#但是loc使用的是标签进行索引,也就是我们上面columns中的名字#不能够说使用类似于[:,3]所有的行,第三列这种写法#如果想要数字进行索引的话需要使用iloc#也就是写成这样的形式iloc[:,3],也就是我们的Sex这一列#由于上面已经将Sex这一列处理过了,我们再进行处理的话,全部的Sex就都会变成0了,所以我们下面这行代码注释掉# data.loc[:,"Sex"]=(data.loc[:,"Sex"]=="male").astype("int")data.head()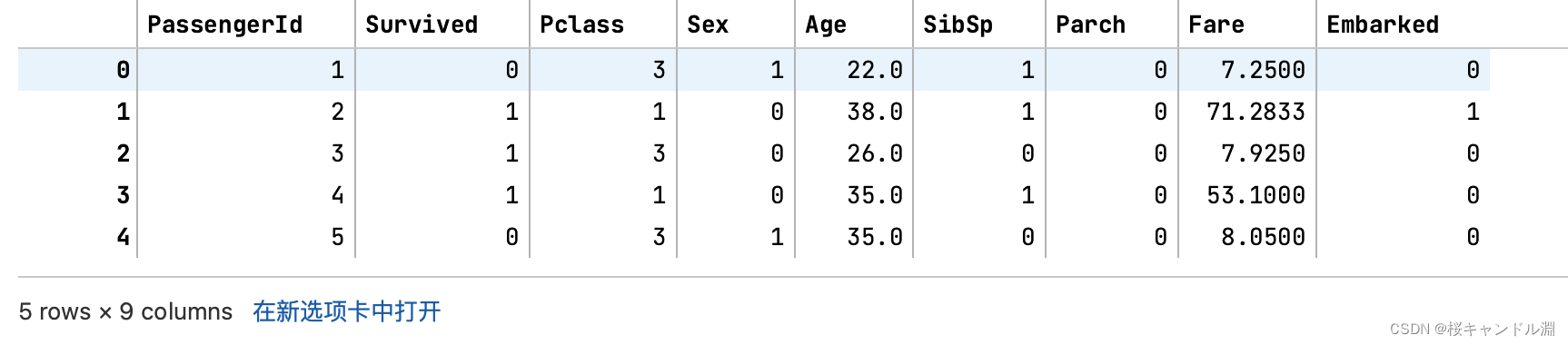
3.将特征和标签分开提取
1.提取特征
#4.将特征和标签分开提取#因为sklearn中特征和标签是分开进行导入的#我们的标签就是Surviced,其他的全部都是特征#取出我们的特征放入x中,其中取出的是所有的行,并且列的columns不等于Survived的数据#由于我们的data.columns !="Survived"返回的是布尔索引,所以也就是将不等于true的列全部都取出来x=data.iloc[:,data.columns !="Survived"]对于上面那行代码的解释
data.columns
data.columns !="Survived"
2.提取标签
y=data.iloc[:,data.columns =="Survived"]y
三、将数据导入模型进行训练
1.划分测试集和训练集
#训练集和测试集的划分from sklearn.model_selection import train_test_splitXtrain,Xtest,Ytrain,Ytest=train_test_split(x,y,test_size=0.3)Xtrain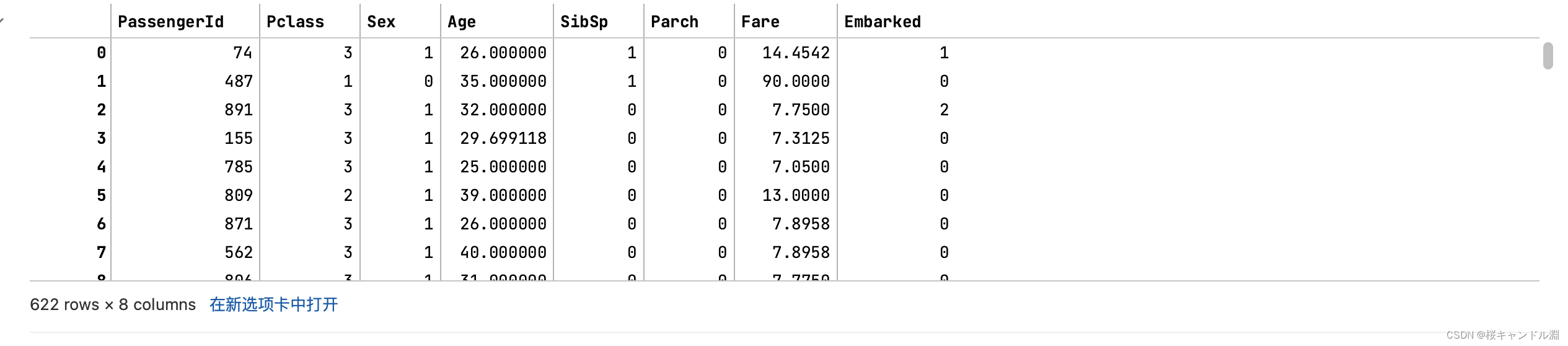
Xtrain.shape 
2.将测试集和训练集中被打乱的索引排序
#这里我们的索引变乱了,我们最好将索引重新排序一下#我们需要将Xtrain的索引转换为0-622也就是我们Xtrain的形状中的第一个元素#Xtrain.index=range(Xtrain.shape[0])#但是我们有四个数据集的索引全部都要修改,所以我们可以采用下面的写法for i in [Xtrain,Xtest,Ytrain,Ytest]: i.index=range(i.shape[0])对于上面代码的解释
Xtrain.shape[0]
#我们观察到索引被纠正过来了Xtrain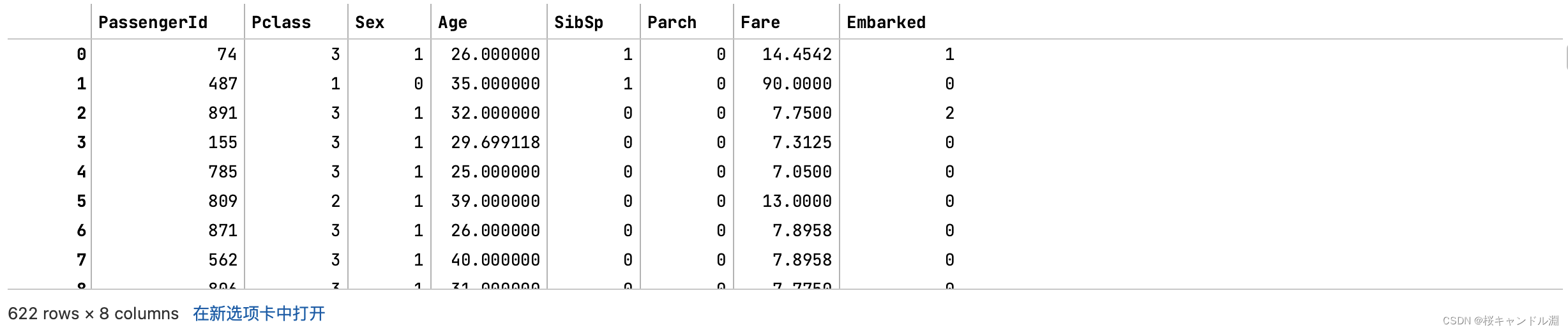
Ytrain 
3.带入模型
#5.带入模型#实例化模型clf=DecisionTreeClassifier(random_state=25)clf=clf.fit(Xtrain,Ytrain)score=clf.score(Xtest,Ytest)score#这个分数并不是很好![]()
四、优化模型
1.使用交叉验证
#使用交叉验证来看看能不能通过多次训练来提高我们预测的分数#导入交叉验证的数据包from sklearn.model_selection import cross_val_scoreclf=DecisionTreeClassifier(random_state=25)#做十次交叉验证,然后取平均值score=cross_val_score(clf,x,y,cv=10).mean()#分数提高了一点点,不大score
2.测试不同的树深度对于分数的影响
1.循环测试,存储每一次的结果
#这个数据比较低,看看应该如何调参,提高打分#用两个空列表来存储我们的训练集和测试集循环出来的分数tr=[]te=[]for i in range(10): #在每一个循环下面都要实例化我们的模型 clf=DecisionTreeClassifier(random_state=25 ,max_depth=i+1 ) clf=clf.fit(Xtrain,Ytrain) #需要同时查看模型在训练集和测试集上面的结果,我们需要打两个分数,分别是训练集的分数和测试集的分数 #训练集的分数 score_tr=clf.score(Xtrain,Ytrain) #测试集的话就是用交叉验证,求一个均值打分 score_te=cross_val_score(clf,x,y,cv=10).mean() #将跑出来的分数导入我们的两个列表中 tr.append(score_tr) te.append(score_te)#打出测试集最大的打分是多少print(max(te))
2.画图分析
#画图#分别绘制训练集和测试集的结果#为什么要同时绘制训练集和测试集的结果?#因为通过这样的数据对比,我们训练集的曲线高于测试集的曲线很多,我们就知道模型是过拟合的#我们就需要剪枝操作#如果测试集上表现很好,也就是分数很高,但是训练集上表现非常糟糕,也就是分数很低,我们就知道是欠拟合的#我们就需要将模型更多地拟合到我们的训练集当中,从而修正我们的模型plt.plot(range(1,11),tr,color="red",label="train")plt.plot(range(1,11),te,color="blue",label="test")#横坐标上显示1-10的整数plt.xticks(range(1,11))#图例plt.legend()#呈现出来plt.show()#从下面的图中可以看到随着树的深度的加深,过拟合的情况越来越严重#其中在3这个深度应该是除了1以外过拟合最轻微的层数了#所以我们应该将最大深度取到3
3.测试看看别的不纯度的指标对模型打分的影响
1.循环测试,存储每一次的结果
#我们可以接着尝试将criterion也就是不纯度的指标换成entropy试试看#但是之前说过拟合的时候不要使用entropy,为什么现在有要使用entropy呢?#因为我们这里的深度为3的这一点,过拟合还不是非常严重,我们把我们的这个指标换成entropy之后#因为这样训练集的分数在3这个点应该会增高,因为它对模型有了更好的拟合#但是测试集会如何变化我们是不知道的#用两个空列表来存储我们的训练集和测试集循环出来的分数tr=[]te=[]for i in range(10): #在每一个循环下面都要实例化我们的模型 clf=DecisionTreeClassifier(random_state=25 ,max_depth=i+1 ,criterion="entropy" ) clf=clf.fit(Xtrain,Ytrain) #需要同时查看模型在训练集和测试集上面的结果,我们需要打两个分数,分别是训练集的分数和测试集的分数 #训练集的分数 score_tr=clf.score(Xtrain,Ytrain) #测试集的话就是用交叉验证,求一个均值打分 score_te=cross_val_score(clf,x,y,cv=10).mean() #将跑出来的分数导入我们的两个列表中 tr.append(score_tr) te.append(score_te)#打出测试集最大的打分是多少print(max(te))
2.画图分析
#画图#分别绘制训练集和测试集的结果#我们就需要将模型更多地拟合到我们的训练集当中,从而修正我们的模型plt.plot(range(1,11),tr,color="red",label="train")plt.plot(range(1,11),te,color="blue",label="test")#横坐标上显示1-10的整数plt.xticks(range(1,11))#图例plt.legend()#呈现出来plt.show()#我们观察到在3这一点我们训练集和测试集的数据非常接近了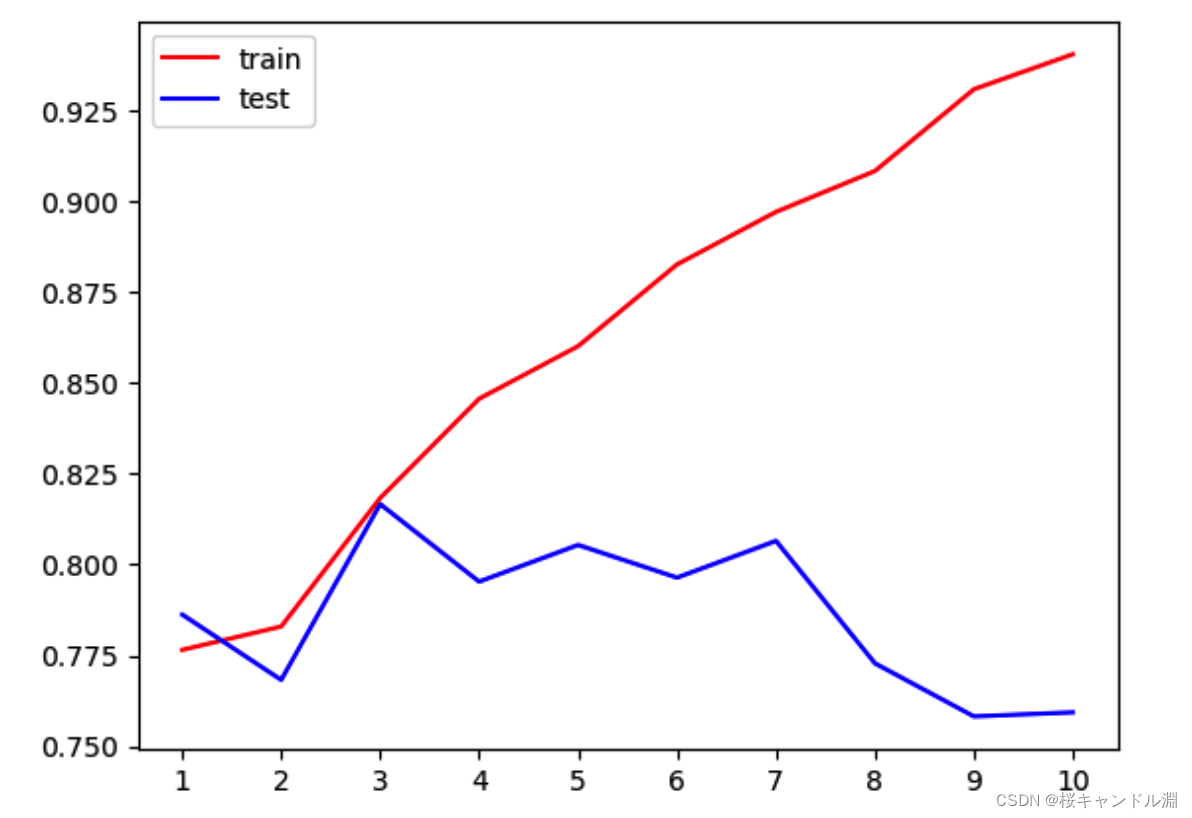
4.使用网格搜索
#但是我们的分数还是只用0.816左右,还需要继续提高#网格搜索:能够帮助我们同时调整多个参数的技术(其本质上是枚举技术)#我们将给网格搜索提供一个字典,字典中是我们一组一组的参数,参数对应我们的取值范围#因为是多个参数交叉进行,所以看上去就跟网格一样#注意:网格搜索的缺点是因为它是把参数一个一个试过去的,所以计算量非常非常大,非常耗时#所以我们在进行网格搜索的时候,传入的数据范围需要非常慎重#第一步:实例化模型clf=DecisionTreeClassifier(random_state=25)#第二步:实例化网格搜索这个类,并填充参数#第一个参数是我们想要运算的模型#第二个参数是需要传入参数和参数取值范围的列表import numpy as np#linspace在你指定的范围内,取出你指定的数字个数字#下面的代码就是在0-0.5之间取50个有顺序的随机数(从小到大排列,但是两个数之间的间隔不一定相同)#我们将其命名为gini_threhold,也就是基尼系数边界的意思#因为基尼系数的取值是0-0.5,gini_threhold=np.linspace(0,0.5,50)#当然也有信息熵的边界取值,范围是0-1#entropy_threhold=np.linspace(0,1,50)#定义parameters#parameters本质上是一串参数和这些参数对应的我们希望网格搜索来搜索的参数的取值范围,也就是一个字典parameters={ #格式:参数的名字,在加上参数的选项 #导入进去之后,网格搜索会帮助我们将所有的这些参数进行匹配,选出一个最好的 #帮criterion这个参数试试看基尼系数和信息熵 "criterion":("gini","entropy") #帮splitter这个参数试试看best和random ,"splitter":("best","random") #对于最大深度,一般是提供一个取值范围的列表 #这里的*是解包的作用,将range(1,10)中的数据提取出来,放入一个list列表中 ,"max_depth":[*range(1,10)] #一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生 #这里我们同样传入一个取值范围的列表,其是从1到50之间,以步长为5进行搜索, # 也就是[1, 6, 11, 16, 21, 26, 31, 36, 41, 46]中哪一个参数更好 ,"min_samples_leaf":[*range(1,50,5)] #min_impurity_decrease信息增益的最小值,当信息增益小于min_impurity_decrease时 #决策树的当前结点将不再进行分支 #信息增益是父节点的信息熵减去子节点的信息熵,,但是要怎么才能确定这个信息增益要在什么程度呢? #这个非常非常难去讨论,所以说这个min_impurity_decrease在不使用网格搜索的情况下是很难去使用的 #这里我们调用之前上面写的基尼系数的边界值 ,"min_impurity_decrease":[*np.linspace(0,0.5,50)]}#第三个参数是想要交叉验证的参数#这里的GridSearch是同时满足了fit,score和交叉验证的三种功能GS=GridSearchCV(clf,parameters,cv=10)#第三步:运算模型#分别传入训练集的数据和标签GS=GS.fit(Xtrain,Ytrain)对上面代码中的解释
*的自动拆包作用
*具有自动拆包的作用
[*range(1,10)]![]()
range(1,10)![]()
linspace和arange的区别
import numpy as np#linspace在你指定的范围内,取出你指定的数字个数字#下面的代码就是在0-0.5之间取50个有顺序的随机数(从小到大排列,但是两个数之间的间隔不一定相同)np.linspace(0,0.5,50)
#注意区分np.arange和linspace,#下面的代码np.range是从[0,0.5)每间隔0.01去一个数据np.arange(0,0.5,0.01)
网格搜索的两个重要接口 GS.best_params_和GS.best_score
#网格搜索的两个重要的接口#第一个GS.best_params_,也就是找出最好的参数#会返回我们输入的参数和参数取值的列表,返回最佳的组合GS.best_params_ 
#第二个重要的参数best_score_#是网格搜索后的模型的评判标准GS.best_score_ ![]()
带入验证
将我们上面网格搜索的最优的参数带入,得到的打分跟我们上面网格搜索的打分是一样的。
clf=DecisionTreeClassifier(criterion="gini" ,random_state=25 ,splitter="random" ,min_impurity_decrease=0.0 ,min_samples_leaf=1 ,max_depth=3)#做十次交叉验证,然后取平均值score=cross_val_score(clf,Xtrain,Ytrain,cv=10).mean()score![]()















